岭回归、Lasso回归和弹性网络
·
Package Build
岭回归(Ridge)、LASSO回归(Lasso)和弹性网络(ElasticNet)都是带正则化(regularization)的线性回归方法,核心目的是:解决多重共线性、过拟合,并控制模型复杂度。
它们的区别本质在于:对模型参数施加不同的惩罚方式。
在线教育场景下,我们经常需要回答这样的问题:哪些学习行为真正影响用户成绩?哪些只是噪声?
普通线性回归在这种场景下往往表现不稳定,而正则化回归(Ridge / LASSO / Elastic Net)正是为此设计。
场景假设
假设,我们需要通过用户在平台上的行为来预测其最终考试成绩(score),用户行为特征如下:
| 特征 | 含义 |
|---|---|
| study_time | 学习时长 |
| video_watch | 视频观看量 |
| practice_rate | 练习完成度 |
| login_days | 登录天数 |
| homework_score | 作业成绩 |
数据集
模拟
我们构造一个包含潜在学习能力的模拟数据。
让study_time与video_watch高度相关、部分变量对成绩无真实贡献、并且存在噪声。
library(tidyverse)
set.seed(123)
n <- 500
# 潜在学习能力(不可观测)
ability <- rnorm(n)
# 构造相关特征
study_time <- 10 + 3*ability + rnorm(n)
video_watch <- study_time*0.8 + rnorm(n, 0, 0.5)
practice_rate <- 0.6*ability + rnorm(n, 0, 0.8)
login_days <- 5 + 1.5*ability + rnorm(n)
homework_score <- 70 + 10*ability + rnorm(n, 0, 3)
# 真实成绩(只有部分变量真正影响)
score <- 60 +
4*study_time +
2*practice_rate +
3*homework_score +
rnorm(n, 0, 10)
df <- data.frame(
score,
study_time,
video_watch,
practice_rate,
login_days,
homework_score
)
探查
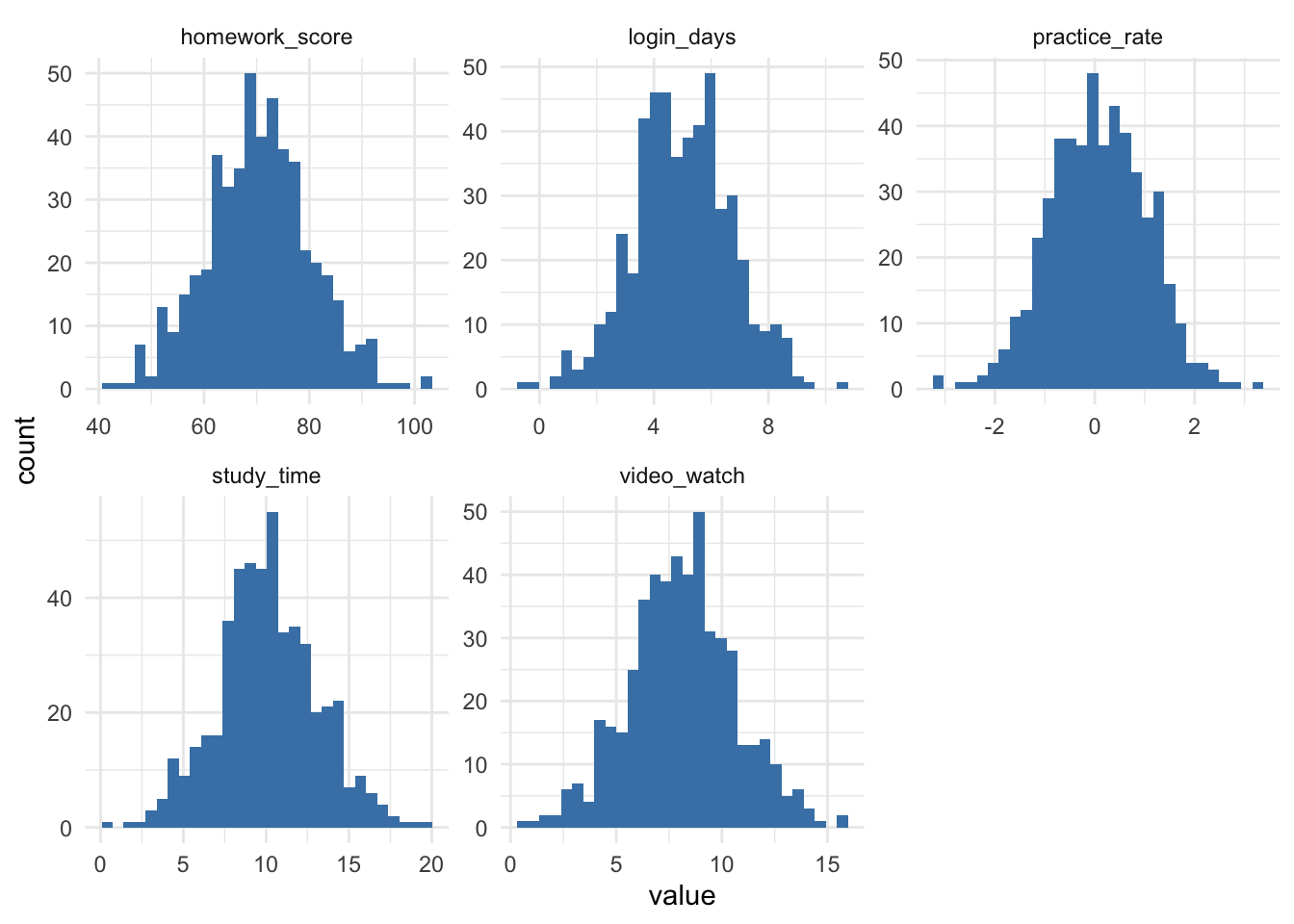
# 变量分布
df |>
pivot_longer(-score) |>
ggplot(aes(value)) +
geom_histogram(bins = 30, fill = "steelblue") +
facet_wrap(~name, scales = "free") +
theme_minimal()
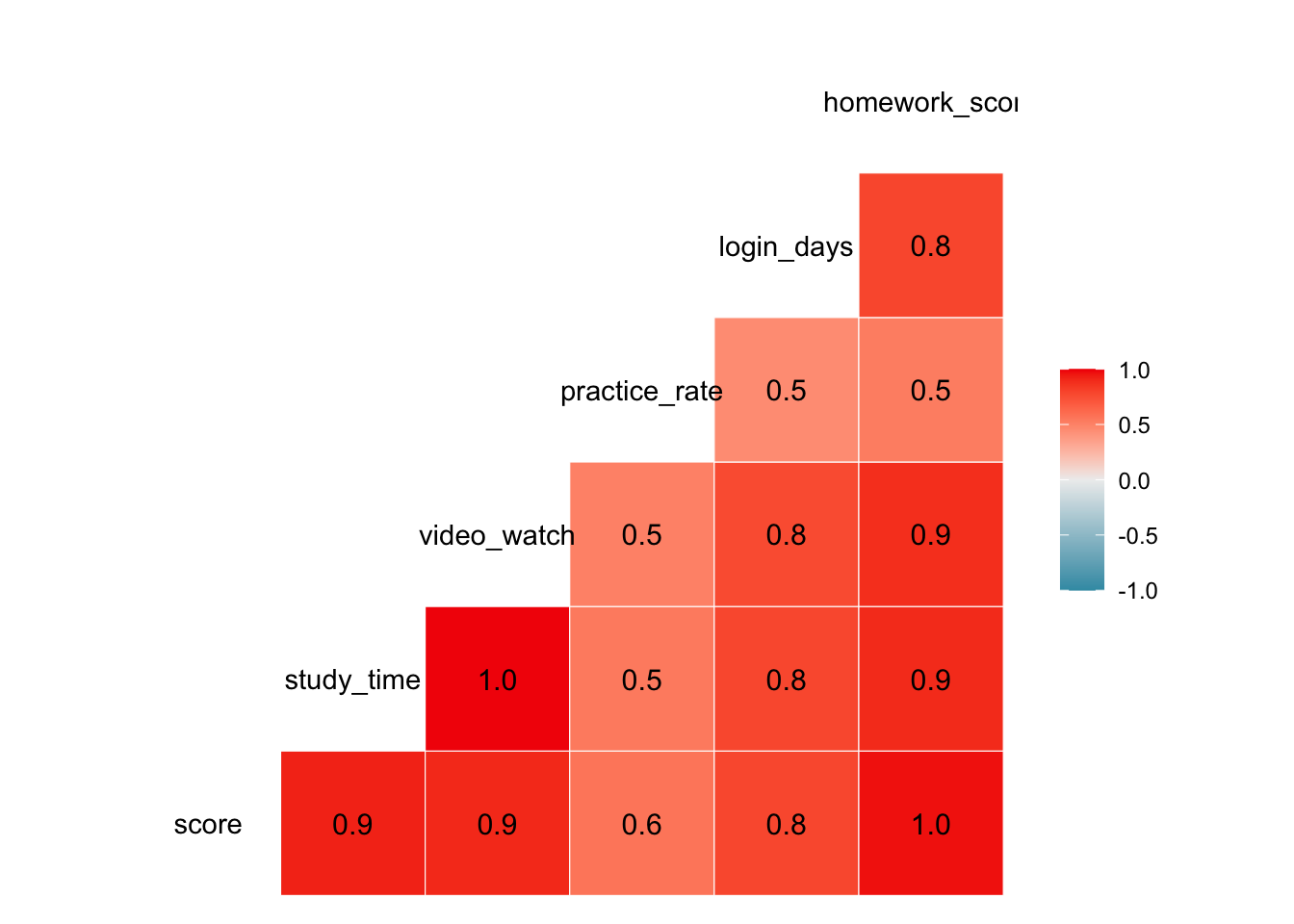
# 变量相关性
GGally::ggcorr(df, label = TRUE)
# 特征与成绩相关性
df |>
pivot_longer(-score) |>
ggplot(aes(value, score)) +
geom_point(alpha = 0.4) +
geom_smooth(method = "lm", se = FALSE) +
facet_wrap(~name, scales = "free") +
theme_minimal()
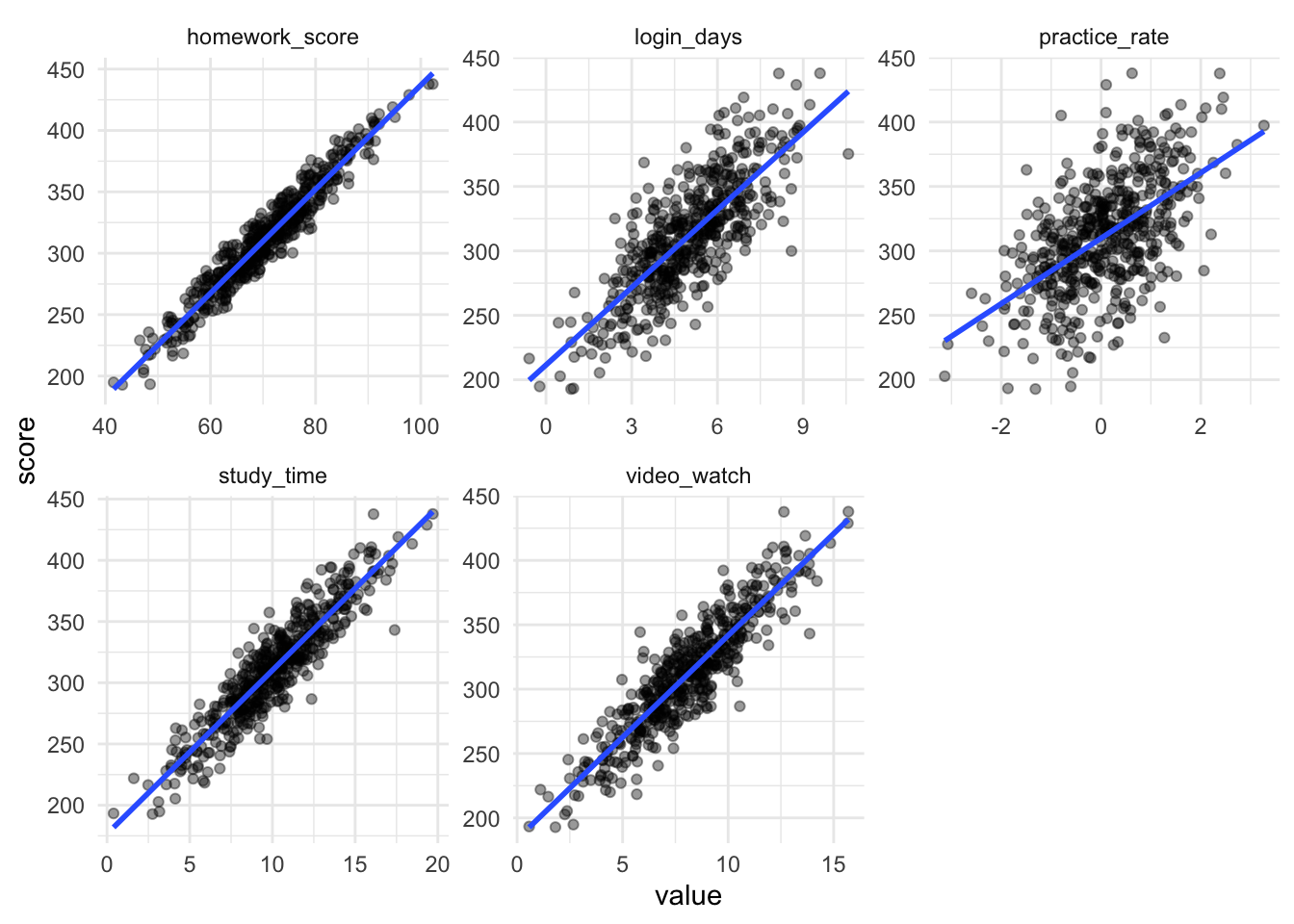
- 可见
study_time与video_watch强相关,study_time与homework_score相关,存在 多重共线性问题 - 多个变量都与成绩相关,难判断因果关系
建模对比
简单线性回归
lm(score ~ ., data = df)
##
## Call:
## lm(formula = score ~ ., data = df)
##
## Coefficients:
## (Intercept) study_time video_watch practice_rate login_days
## 56.5695 4.3658 -0.5375 2.0594 0.1158
## homework_score
## 3.0465
基于最小二乘法的目标(最小化预测误差)在此场景中存在以下问题:
- 当
video_watch≈study_time,模型无法稳定分配权重,系数波动大。 - 容易过拟合,特征多 → 方差大 → 泛化差。
- 无变量选择能力,无法识别哪些行为真正重要。
正则化方法对比
| 方法 | 会删除变量 | 对共线性稳定 | 适合目标 |
|---|---|---|---|
| OLS | ❌ | ❌ | 基础拟合 |
| Ridge | ❌ | ✅ | 预测 |
| LASSO | ✅ | 一般 | 解释 |
| Elastic Net | ✅ | ✅ | 综合 |
library(glmnet)
x <- model.matrix(score ~ . -1, df)
y <- df$score
# 训练三种模型
cv_ridge <- cv.glmnet(x, y, alpha = 0)
cv_lasso <- cv.glmnet(x, y, alpha = 1)
cv_en <- cv.glmnet(x, y, alpha = 0.5)
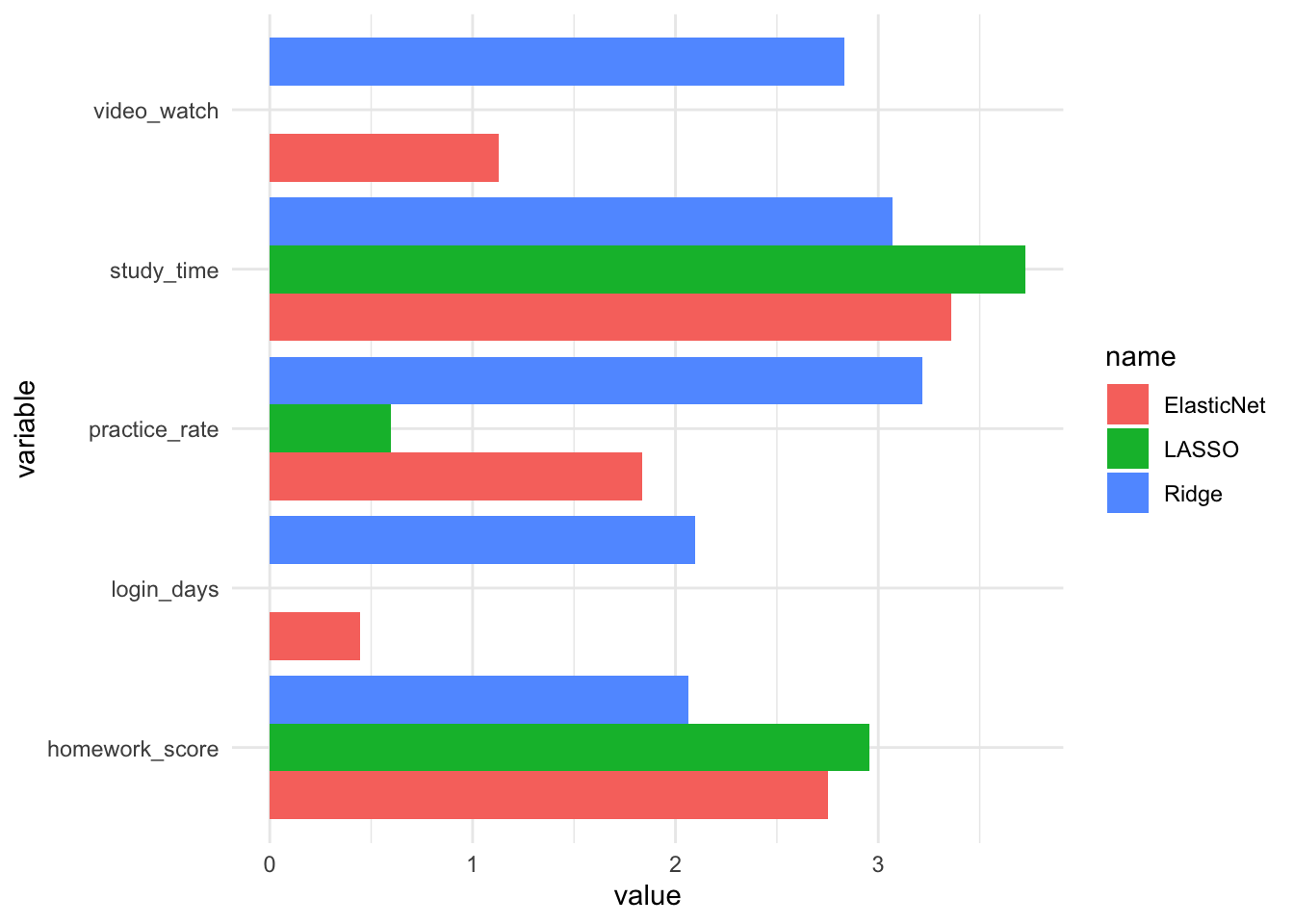
# 系数对比
coef_df <- tibble(
variable = rownames(coef(cv_ridge)),
Ridge = as.numeric(coef(cv_ridge)),
LASSO = as.numeric(coef(cv_lasso)),
ElasticNet = as.numeric(coef(cv_en))
) |>
pivot_longer(-variable)
coef_df |>
filter(variable != "(Intercept)") |>
ggplot(aes(variable, value, fill = name)) +
geom_col(position="dodge") +
coord_flip() +
theme_minimal()
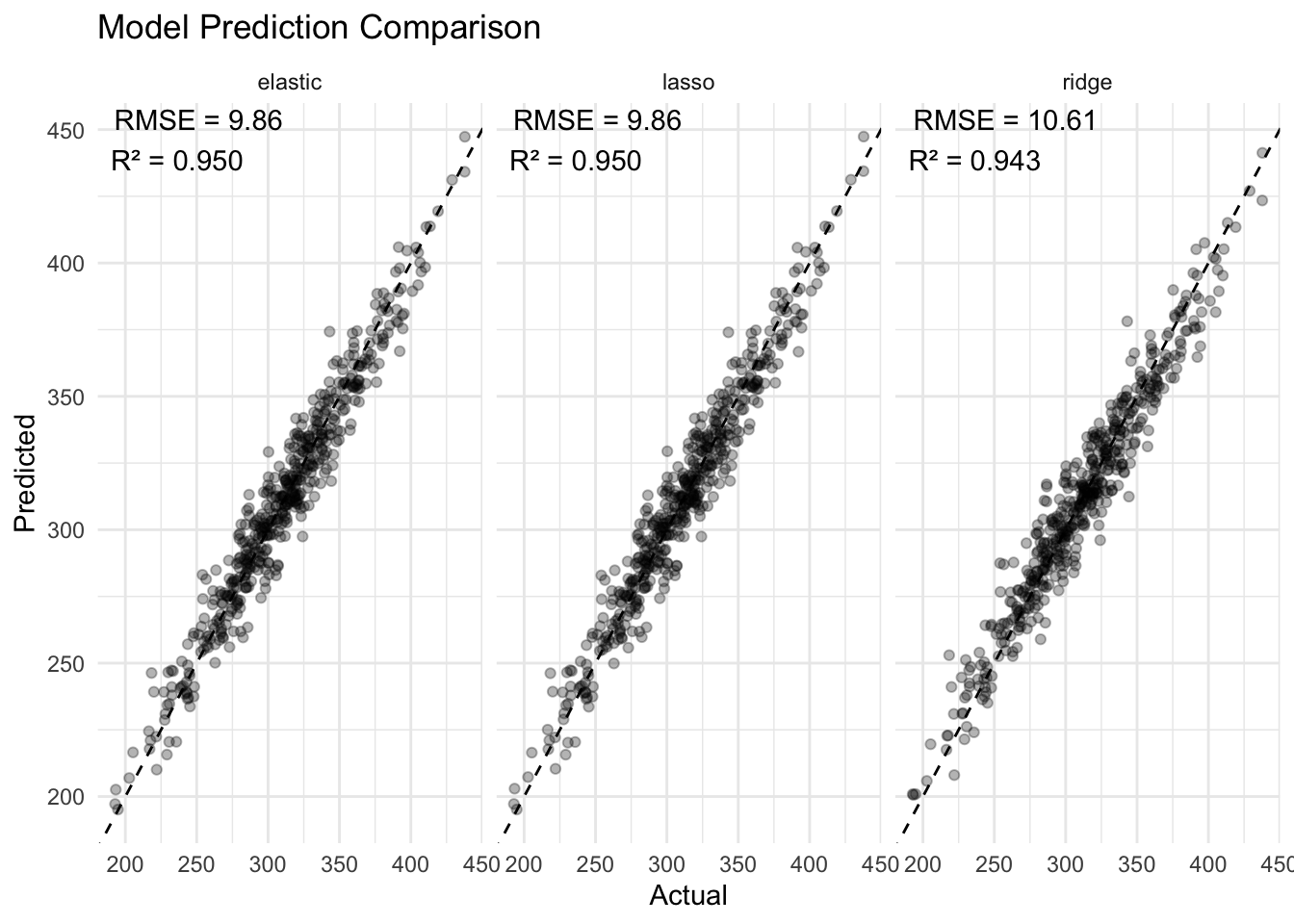
# 预测表现对比
pred <- tibble(
actual = y,
ridge = as.numeric(predict(cv_ridge, x, s="lambda.min")),
lasso = as.numeric(predict(cv_lasso, x, s="lambda.min")),
elastic = as.numeric(predict(cv_en, x, s="lambda.min"))
) |>
pivot_longer(-actual, names_to = "model", values_to = "pred")
# 计算模型指标(RMSE + R2)
metric_df <- pred |>
group_by(model) |>
summarise(
rmse = sqrt(mean((actual - pred)^2)),
r2 = cor(actual, pred)^2,
.groups = "drop"
) |>
mutate(label = sprintf("RMSE = %.2f\nR² = %.3f", rmse, r2))
# 绘图
pred |>
ggplot(aes(actual, pred)) +
geom_point(alpha = 0.3) +
geom_abline(linetype = 2) +
facet_wrap(~model) +
geom_text(
data = metric_df,
aes(x = -Inf, y = Inf, label = label),
hjust = -0.1,
vjust = 1.1,
inherit.aes = FALSE
) +
labs(
x = "Actual",
y = "Predicted",
title = "Model Prediction Comparison"
) +
theme_minimal()
拓展
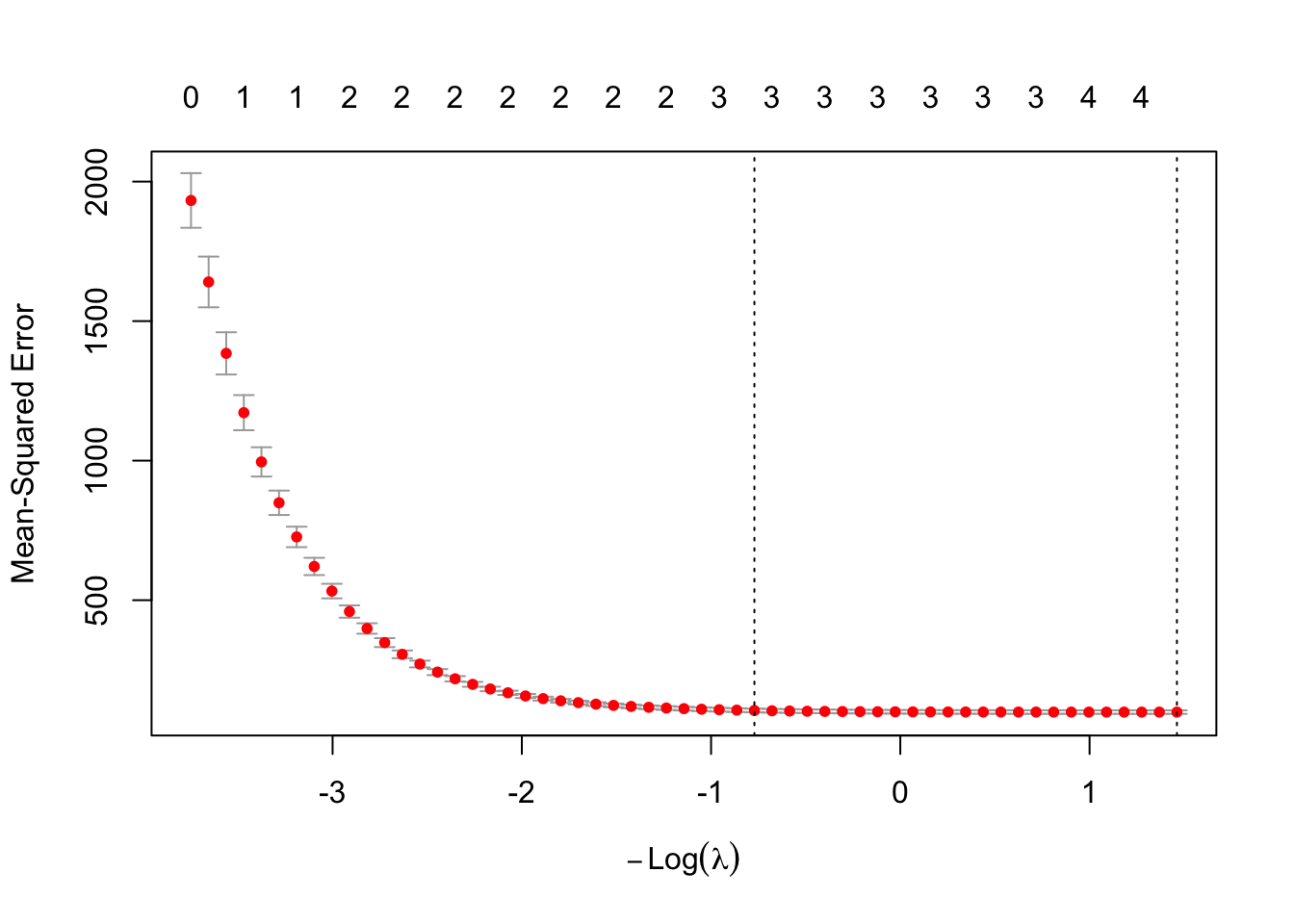
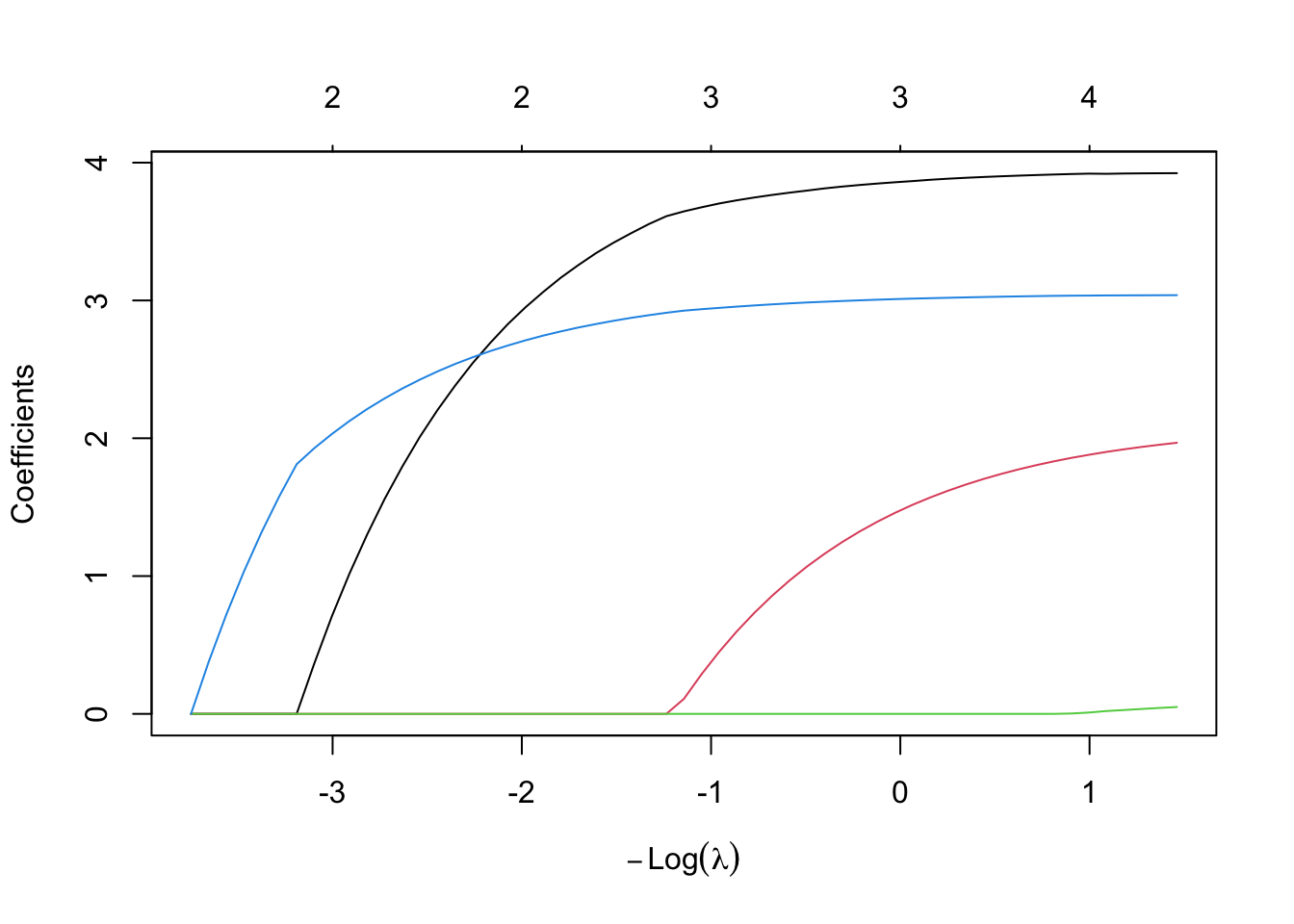
λ该怎么选择?
# λ 路径
# 图含义:横轴-log(λ) 、纵轴-系数大小 、每条线-各变量
# λ增大 → 系数逐渐收缩 → 部分变0
plot(cv_lasso$glmnet.fit, xvar = "lambda")
# 交叉验证选择最优λ
# 原理:
# 1.将数据分成 k 份
# 2.轮流训练验证
# 3.选择预测误差最小的 λ
cv_lasso <- cv.glmnet(x, y, alpha = 1)
plot(cv_lasso)