SDID合成双重差分法
·
Xiebro
数据集
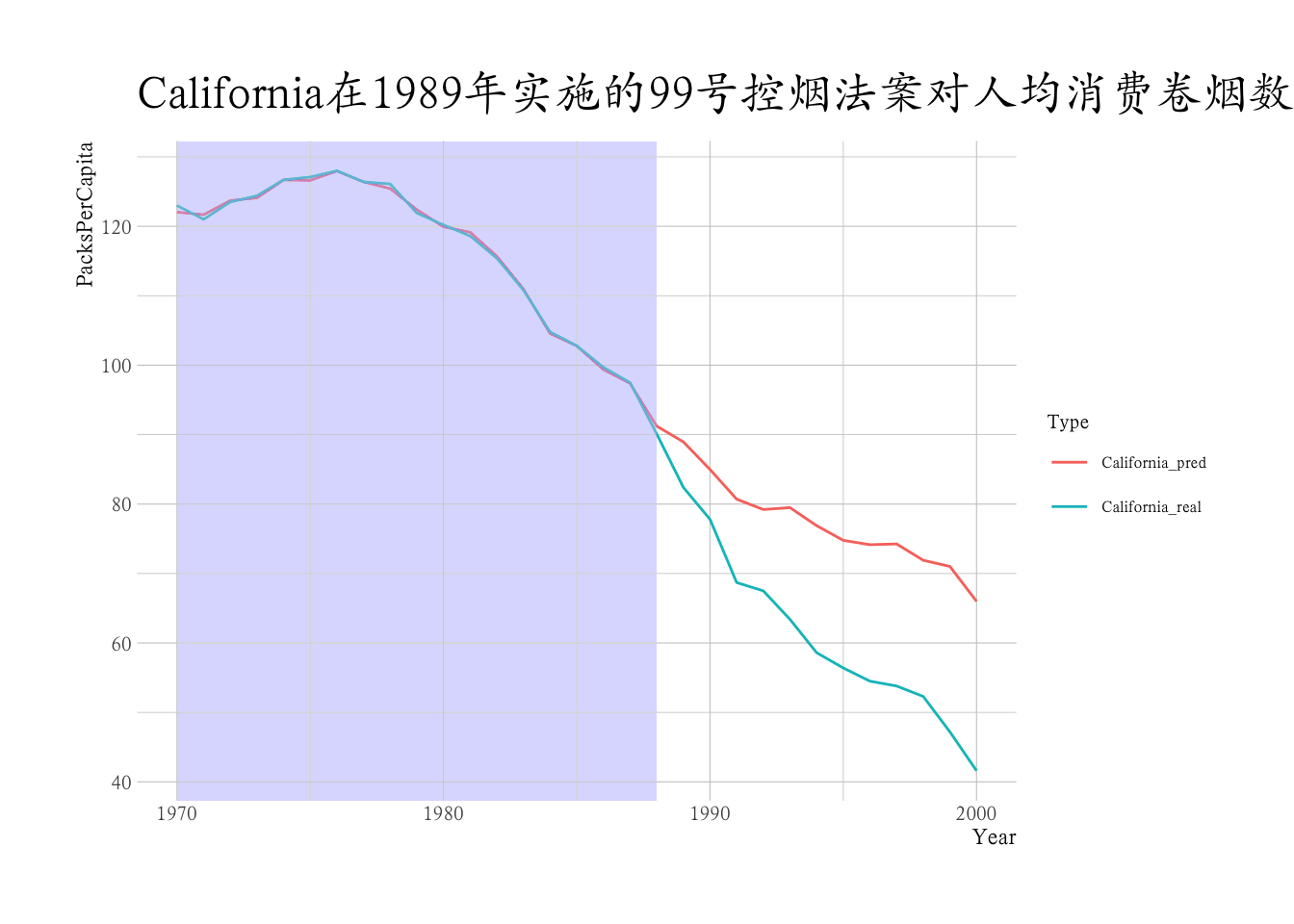
- 1989年,California实行了一项名为“99号提案”的选民倡议,该提案是美国第一个现代大规模烟草控制项目,该法案在后续引发了一系列关于室内清洁空气的地方立法;
- 美国各州从 1970 年开始有完整的香烟消费的数据,随着健康理念的深入,到2000 年大部分州也实施了禁烟措施。因此该案例的观察周期是从1970年至2000年之间。出于研究准确性的考虑,删除了部分州的数据,最后样本池中剩下38个州,数据集中包含了年份(Year),人均消费卷烟数(PacksPerCapita)。
library(tidyverse)
dat <- read.csv("datasets/california_prop99.csv")
dat <-
dat |>
pivot_wider(id_cols = "Year",
names_from = "State",
values_from = "PacksPerCapita")
dat |> glimpse()
## Rows: 31
## Columns: 40
## $ Year <int> 1970, 1971, 1972, 1973, 1974, 1975, 1976, 1977, 1978,…
## $ Alabama <dbl> 89.8, 95.4, 101.1, 102.9, 108.2, 111.7, 116.2, 117.1,…
## $ Arkansas <dbl> 100.3, 104.1, 103.9, 108.0, 109.7, 114.8, 119.1, 122.…
## $ Colorado <dbl> 124.8, 125.5, 134.3, 137.9, 132.8, 131.0, 134.2, 132.…
## $ Connecticut <dbl> 120.0, 117.6, 110.8, 109.3, 112.4, 110.2, 113.4, 117.…
## $ Delaware <dbl> 155.0, 161.1, 156.3, 154.7, 151.3, 147.6, 153.0, 153.…
## $ Georgia <dbl> 109.9, 115.7, 117.0, 119.8, 123.7, 122.9, 125.9, 127.…
## $ Idaho <dbl> 102.4, 108.5, 126.1, 121.8, 125.6, 123.3, 125.1, 125.…
## $ Illinois <dbl> 124.8, 125.6, 126.6, 124.4, 131.9, 131.8, 134.4, 134.…
## $ Indiana <dbl> 134.6, 139.3, 149.2, 156.0, 159.6, 162.4, 166.6, 173.…
## $ Iowa <dbl> 108.5, 108.4, 109.4, 110.6, 116.1, 120.5, 124.4, 125.…
## $ Kansas <dbl> 114.0, 102.8, 111.0, 115.2, 118.6, 123.4, 127.7, 127.…
## $ Kentucky <dbl> 155.8, 163.5, 179.4, 201.9, 212.4, 223.0, 230.9, 229.…
## $ Louisiana <dbl> 115.9, 119.8, 125.3, 126.7, 129.9, 133.6, 139.6, 140.…
## $ Maine <dbl> 128.5, 133.2, 136.5, 138.0, 142.1, 140.7, 144.9, 145.…
## $ Minnesota <dbl> 104.3, 116.4, 96.8, 106.8, 110.6, 111.5, 116.7, 117.2…
## $ Mississippi <dbl> 93.4, 105.4, 112.1, 115.0, 117.1, 116.8, 120.9, 122.1…
## $ Missouri <dbl> 121.3, 127.6, 130.0, 132.1, 135.4, 135.6, 139.5, 140.…
## $ Montana <dbl> 111.2, 115.6, 122.2, 119.9, 121.9, 123.7, 124.9, 127.…
## $ Nebraska <dbl> 108.1, 108.6, 104.9, 106.6, 110.5, 114.1, 118.1, 117.…
## $ Nevada <dbl> 189.5, 190.5, 198.6, 201.5, 204.7, 205.2, 201.4, 190.…
## $ `New Hampshire` <dbl> 265.7, 278.0, 296.2, 279.0, 269.8, 269.1, 290.5, 278.…
## $ `New Mexico` <dbl> 90.0, 92.6, 99.3, 98.9, 100.3, 103.1, 102.4, 102.4, 1…
## $ `North Carolina` <dbl> 172.4, 187.6, 214.1, 226.5, 227.3, 226.0, 230.2, 217.…
## $ `North Dakota` <dbl> 93.8, 98.5, 103.8, 108.7, 110.5, 117.9, 125.4, 122.2,…
## $ Ohio <dbl> 121.6, 124.6, 124.4, 120.5, 122.1, 122.5, 124.6, 127.…
## $ Oklahoma <dbl> 108.4, 115.4, 121.7, 124.1, 130.5, 132.9, 138.6, 140.…
## $ Pennsylvania <dbl> 107.3, 106.3, 109.0, 110.7, 114.2, 114.6, 118.8, 120.…
## $ `Rhode Island` <dbl> 123.9, 123.2, 134.4, 142.0, 146.1, 154.7, 150.2, 148.…
## $ `South Carolina` <dbl> 103.6, 115.0, 118.7, 125.5, 129.7, 130.5, 136.8, 137.…
## $ `South Dakota` <dbl> 92.7, 96.7, 103.0, 103.5, 108.4, 113.5, 116.7, 115.6,…
## $ Tennessee <dbl> 99.8, 106.3, 111.5, 109.7, 114.8, 117.4, 121.7, 124.6…
## $ Texas <dbl> 106.4, 108.9, 108.6, 110.4, 114.7, 116.0, 121.4, 124.…
## $ Utah <dbl> 65.5, 67.7, 71.3, 72.7, 75.6, 75.8, 77.9, 78.0, 79.6,…
## $ Vermont <dbl> 122.6, 124.4, 138.0, 146.8, 151.8, 155.5, 171.1, 169.…
## $ Virginia <dbl> 124.3, 128.4, 137.0, 143.1, 149.6, 152.7, 158.1, 157.…
## $ `West Virginia` <dbl> 114.5, 111.5, 117.5, 116.6, 119.9, 123.2, 129.7, 133.…
## $ Wisconsin <dbl> 106.4, 105.4, 108.8, 109.5, 111.8, 113.5, 115.4, 117.…
## $ Wyoming <dbl> 132.2, 131.7, 140.0, 141.2, 145.8, 160.7, 161.5, 160.…
## $ California <dbl> 123.0, 121.0, 123.5, 124.4, 126.7, 127.1, 128.0, 126.…
SDID
即Synthetic Difference In Differences,是一种利用合成控制组的方式来评估政策干预效果的分析方法。其基本原理是将政策实施地区的观测结果与一个合成控制组进行比较,以便更准确地衡量政策效果。
- 选择一个与政策实施地区在政策实施前相似的合成控制组;
- 使用控制组的数据建立预测模型来估计政策实施地区在政策实施前的预期结果;
- 然后比较政策实施地区的观测结果与合成控制组的预测结果,评估政策干预效果。
library(glmnet)
# 使用法按实施前(即1989年前)的样本进行拟合
dat_sub <- subset(dat, Year < 1989)
# 以California作为Y(因变量),其它州作为X(自变量),进行Lasso回归
Y <- dat_sub |> pull(California)
X <- dat_sub |> select(-c(Year, California)) |> as.matrix()
glm <- cv.glmnet(y = Y,
x = X,
family = "gaussian")
print(glm)
##
## Call: cv.glmnet(x = X, y = Y, family = "gaussian")
##
## Measure: Mean-Squared Error
##
## Lambda Index Measure SE Nonzero
## min 0.1089 100 4.091 1.841 11
## 1se 0.8831 55 5.797 2.762 6
# 提取交叉验证中选择的最佳Lambda值对应的模型系数
coef(glm, s = "lambda.min") |> round(2)
## 39 x 1 sparse Matrix of class "dgCMatrix"
## s1
## (Intercept) 6.59
## Alabama .
## Arkansas .
## Colorado 0.05
## Connecticut 0.17
## Delaware .
## Georgia .
## Idaho 0.04
## Illinois 0.16
## Indiana .
## Iowa .
## Kansas .
## Kentucky .
## Louisiana .
## Maine .
## Minnesota .
## Mississippi .
## Missouri .
## Montana 0.14
## Nebraska 0.14
## Nevada 0.17
## New Hampshire 0.01
## New Mexico .
## North Carolina .
## North Dakota .
## Ohio .
## Oklahoma .
## Pennsylvania .
## Rhode Island .
## South Carolina .
## South Dakota .
## Tennessee -0.24
## Texas .
## Utah 0.22
## Vermont .
## Virginia .
## West Virginia 0.07
## Wisconsin .
## Wyoming .
# 合成控制组
X_all <-
dat |>
select(-c(Year, California)) |>
as.matrix()
lambda_min <- glm$lambda.min
dat_new <-
data.frame(
Year = dat$Year,
California_real = dat$California,
California_pred = predict(glm, newx = X_all, s = lambda_min)[,1]
) |>
gather("Type", "PacksPerCapita", -Year)
head(dat_new, 10)
## Year Type PacksPerCapita
## 1 1970 California_real 123.0
## 2 1971 California_real 121.0
## 3 1972 California_real 123.5
## 4 1973 California_real 124.4
## 5 1974 California_real 126.7
## 6 1975 California_real 127.1
## 7 1976 California_real 128.0
## 8 1977 California_real 126.4
## 9 1978 California_real 126.1
## 10 1979 California_real 121.9
# 可视化
library(hrbrthemes)
theme_set(theme_ipsum(base_family = "Kai",
base_size = 8))
dat_new |>
ggplot(aes(x = Year, y = PacksPerCapita)) +
geom_line(aes(col = Type)) +
geom_rect(xmin = 1970,
xmax = 1988,
ymin = -Inf,
ymax = Inf,
fill = "lightblue",
alpha = 0.01) +
ggtitle("California在1989年实施的99号控烟法案对人均消费卷烟数的影响")