DID结果的显著性
·
Xiebro
构造演示数据
library(tidyverse)
# Generate dummy data ----
set.seed(42)
# number of observations
enroll = 5000
generate_vector <- function(N, prob1, prob2) {
term <- c(rep("term1", N), rep("term2", N))
befr <- rbinom(N, size = 1, prob = prob1)
aftr <- rbinom(N, size = 1, prob = prob2)
# return
data.frame(term = term, renewal = c(befr, aftr))
}
grpA <- generate_vector(enroll, .10, .11)
grpB <- generate_vector(enroll, .11, .13)
# working data frame
df <-
bind_rows(grpA, grpB, .id = "group") %>%
mutate(group = if_else(group == 1, "A", "B")) %>%
as_tibble()
# data validation
df %>%
group_by(group, term) %>%
summarise(mu = mean(renewal),
.groups = "drop")
## # A tibble: 4 × 3
## group term mu
## <chr> <chr> <dbl>
## 1 A term1 0.108
## 2 A term2 0.11
## 3 B term1 0.109
## 4 B term2 0.128
DID结果
# find DiD
df %>%
group_by(group, term) %>%
summarise(mu = mean(renewal),
.groups = "drop") %>%
group_by(group) %>%
summarise(diff = diff(mu),
.groups = "drop") %>%
summarise(did = diff(diff),
.groups = "drop") %>%
pull(did)
## [1] 0.0176
方法一:Bootstrap模拟P值
# Simulation by manual bootstapping ----
N = 5000
trials = 10000
# takes about 60s
res <-
map_dbl(1:trials, {
~ df %>%
group_by(group, term) %>%
# randomization
sample_n(size = N, replace = TRUE) %>%
summarise(mu = mean(renewal),
.groups = "keep") %>%
group_by(group) %>%
summarise(diff = diff(mu),
.groups = "drop") %>%
summarise(did = diff(diff),
.groups = "drop") %>%
pull(did)
})
# find p-value
pval <- length(which(res < 0)) / length(res)
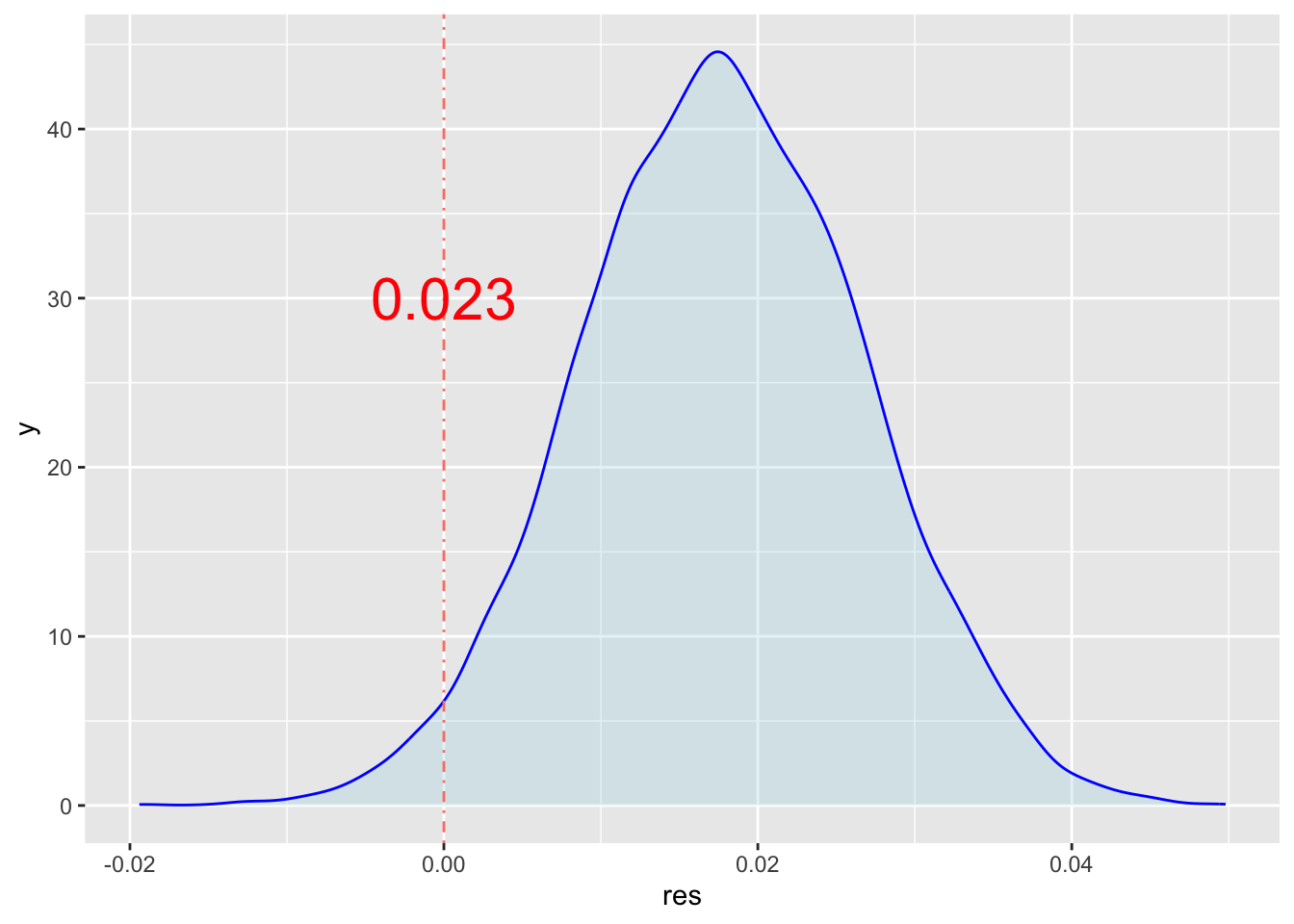
# 模拟单边检验P值结果:
NULL %>%
ggplot(aes(res)) +
geom_density(fill = "lightblue", col = "blue", alpha = .3) +
geom_vline(xintercept = 0, lty = 4, col = "salmon") +
geom_text(aes(
x = 0,
y = 30,
label = format(pval, digits = 2)),
col = "red", size = 8)
方法二:回归模型参数
dat <-
df %>%
mutate(treated = ifelse(group == "B", 1L, 0L),
term = ifelse(term == "term2", 1L, 0L),
did = term * treated) |>
select(term, treated, did, renewal)
sample_n(dat, 5)
## # A tibble: 5 × 4
## term treated did renewal
## <int> <int> <int> <int>
## 1 1 1 1 0
## 2 0 0 0 0
## 3 1 1 1 0
## 4 0 0 0 0
## 5 0 1 0 0
# 进行DID估计,并使用稳健标准误
library(estimatr)
fit <- lm_robust(renewal ~ term + treated + did, data = dat)
# 模型结果(P值为双边检验)
summary(fit)
##
## Call:
## lm_robust(formula = renewal ~ term + treated + did, data = dat)
##
## Standard error type: HC2
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
## (Intercept) 0.1082 0.004393 24.62756 5.898e-132 9.959e-02 0.11681 19996
## term 0.0018 0.006236 0.28865 7.729e-01 -1.042e-02 0.01402 19996
## treated 0.0006 0.006221 0.09645 9.232e-01 -1.159e-02 0.01279 19996
## did 0.0176 0.008980 1.95991 5.002e-02 -1.514e-06 0.03520 19996
##
## Multiple R-squared: 0.0006895 , Adjusted R-squared: 0.0005396
## F-statistic: 4.293 on 3 and 19996 DF, p-value: 0.004918